湖倉一體技術調研 Apache Hudi、Iceberg與Delta Lake在數據處理與存儲支持服務上的對比分析
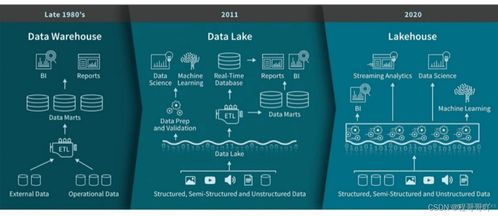
隨著數據湖架構在企業中的廣泛應用,數據管理與查詢效率的挑戰日益凸顯。湖倉一體(Lakehouse)作為一種新興的數據架構范式,旨在融合數據湖的靈活性與數據倉庫的高性能管理能力。在這一領域,Apache Hudi、Apache Iceberg和Delta Lake已成為三大主流開源解決方案,它們均提供了ACID事務、數據版本控制、模式演進等關鍵特性,但在設計哲學、數據處理能力和存儲支持服務上存在差異。本文將對這三者進行綜合對比分析,以期為技術選型提供參考。
一、核心特性與設計哲學概述
- Apache Hudi
- 設計目標:專注于實時數據湖的增量處理,強調低延遲的數據更新和刪除能力,特別適用于需要近實時數據攝入和變更數據捕獲(CDC)的場景。
- 關鍵特性:支持插入、更新、刪除操作;提供兩種表類型(Copy-on-Write和Merge-on-Read);內置索引機制加速數據定位。
- Apache Iceberg
- 設計目標:致力于提供高性能、可擴展的表格式抽象,強調查詢優化和跨引擎兼容性,適合大規模分析工作負載。
- 關鍵特性:隱藏分區、模式演進、快照隔離;通過元數據層實現高效的數據剪枝和謂詞下推。
- Delta Lake
- 設計目標:由Databricks主導,旨在為Apache Spark提供可靠的數據湖存儲層,強調事務一致性與數據質量管控。
- 關鍵特性:ACID事務、數據版本歷史、數據驗證(Schema Enforcement)和時間旅行(Time Travel)。
二、數據處理能力對比
- 數據更新與刪除
- Hudi:通過索引支持高效的更新/刪除,適合頻繁變更的場景。Merge-on-Read模式可平衡讀寫性能。
- Iceberg:支持行級更新和刪除,但依賴于引擎實現(如Spark 3.0+),更側重于批量處理優化。
- Delta Lake:提供完整的更新/刪除接口,與Spark深度集成,操作較為直觀。
- 查詢性能
- Hudi:索引加速點查和增量查詢;Merge-on-Read可能增加讀取開銷。
- Iceberg:通過元數據優化(如分區演化、文件統計)大幅提升掃描效率,適合復雜分析查詢。
- Delta Lake:利用數據統計和索引優化查詢,但性能高度依賴Spark優化器。
- 流批一體支持
- Hudi:原生支持流式寫入和增量拉取,與Flink、Spark Streaming集成良好。
- Iceberg:通過“快照”概念支持流式讀取,但流寫入需依賴引擎適配。
- Delta Lake:提供結構化流處理集成,支持連續處理和批處理統一。
三、存儲支持與服務生態
- 存儲兼容性
- 三者均支持云對象存儲(如AWS S3、Azure Blob Storage、Google Cloud Storage)和HDFS,但實現細節不同:
- Hudi:對云存儲有專門優化(如一致性保證)。
- Iceberg:通過原子操作抽象層減少存儲依賴。
- Delta Lake:依賴事務日志保證一致性,對云存儲有較好適配。
- 計算引擎集成
- Hudi:支持Spark、Flink、Hive、Presto/Trino等,生態較為開放。
- Iceberg:設計為引擎無關,已集成Spark、Flink、Trino、Hive、Impala等,兼容性最廣。
- Delta Lake:深度綁定Spark,對其他引擎支持需通過第三方連接器(如Delta Standalone)。
- 管理與運維工具
- Hudi:提供命令行工具和元數據管理,但企業級功能較弱。
- Iceberg:擁有豐富的元數據API,易于構建自定義管理工具。
- Delta Lake:在Databricks平臺內提供完善的UI、監控和優化服務,開源版本功能相對有限。
四、適用場景
- Apache Hudi:適用于需要近實時數據更新、CDC處理或增量管道的場景,如實時數倉、物聯網數據處理。
- Apache Iceberg:適合大規模數據分析、多引擎共享數據的場景,特別是對查詢性能和分區靈活性要求較高的企業。
- Delta Lake:適合以Spark為核心的技術棧,強調數據質量與事務一致性,且可受益于Databricks商業支持的環境。
五、結論
Apache Hudi、Iceberg和Delta Lake均推動了湖倉一體架構的成熟,但各有側重。Hudi在實時處理上表現突出,Iceberg在查詢優化和跨引擎兼容性上更具優勢,而Delta Lake則提供了與Spark生態的最優集成。企業在選型時需綜合考慮現有技術棧、數據場景(流批比例、更新頻率)和長期維護成本。隨著湖倉一體標準化進程的推進,三者可能會進一步融合或形成互補生態,為用戶提供更統一的數據管理體驗。
如若轉載,請注明出處:http://m.souvv.com/product/64.html
更新時間:2026-02-19 17:57:02